1.1 Genes, DNA and central dogma
A central concept that will come up again and again is “the gene”. Before we can explain that, we need to introduce a few other concepts that are important to understand the gene concept. The human body is made up of billions of cells. These cells specialize in different tasks. For example, in the liver there are cells that help produce enzymes to break toxins. In the heart, there are specialized muscle cells that make the heart beat. Yet, all these different kinds of cells come from a single-celled embryo. All the instructions to make different kinds of cells are contained within that single cell and with every division of that cell, those instructions are transmitted to new cells. These instructions can be coded into a string – a molecule of DNA, a polymer made of recurring units called nucleotides. The four nucleotides in DNA molecules, Adenine, Guanine, Cytosine and Thymine (coded as four letters: A, C, G, and T) in a specific sequence, store the information for life. DNA is organized in a double-helix form where two complementary polymers interlace with each other and twist into the familiar helical shape.
1.1.1 What is a genome?
The full DNA sequence of an organism, which contains all the hereditary information, is called a genome. The genome contains all the information to build and maintain an organism. Genomes come in different sizes and structures. Our genome is not only a naked stretch of DNA. In eukaryotic cells, DNA is wrapped around proteins (histones) forming higher-order structures like nucleosomes which make up chromatins and chromosomes (see Figure 1.1).
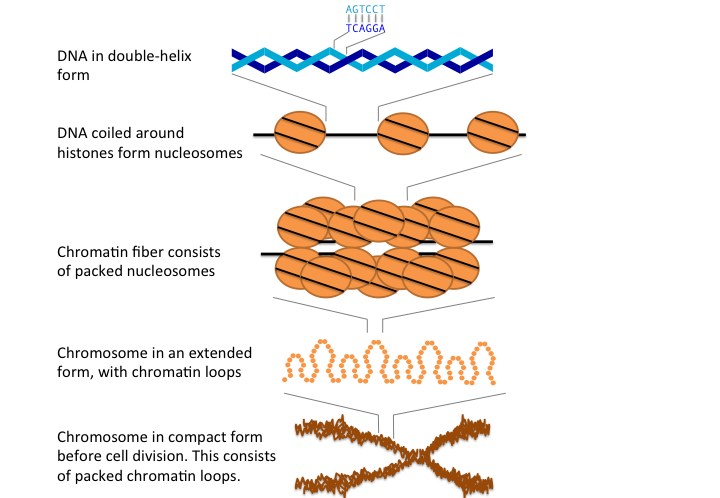
FIGURE 1.1: Chromosome structure in animals.
There might be several chromosomes depending on the organism. However, in some species (such as most prokaryotes) DNA is stored in a circular form. The size of the genome between species differs too. The human genome has 46 chromosomes and over 3 billion base-pairs, whereas the wheat genome has 42 chromosomes and 17 billion base-pairs; both genome size and chromosome numbers are variable between different organisms. Genome sequences of organisms are obtained using sequencing technology. With this technology, fragments of the DNA sequence from the genome, called reads, are obtained. Larger chunks of the genome sequence are later obtained by stitching the initial fragments to larger ones by using the overlapping reads. The latest sequencing technologies made genome sequencing cheaper and faster. These technologies output more reads, longer reads and more accurate reads.
The estimated cost of the first human genome was $300 million in 1999–2000; today a high-quality human genome can be obtained for $1500. Since the costs are going down, researchers and clinicians can generate more data. This drives up the costs for data storage and also drives up the demand for qualified people to analyze genomic data. This was one of the motivations behind writing this book.
1.1.2 What is a gene?
In the genome, there are specific regions containing the precise information that encodes for physical products of genetic information. A region in the genome with this information is traditionally called a “gene”. However, the precise definition of the gene is still developing. According to the classical textbooks in molecular biology, a gene is a segment of a DNA sequence corresponding to a single protein or to a single catalytic and structural RNA molecule (Alberts, Bray, Lewis, et al. 2002). A modern definition is: “A region (or regions) that includes all of the sequence elements necessary to encode a functional transcript” (Eilbeck, Lewis, Mungall, et al. 2005). No matter how variable the definitions are, all agree on the fact that genes are basic units of heredity in all living organisms.
All cells use their hereditary information in the same way most of the time; the DNA is replicated to transfer the information to new cells. If activated, the genes are transcribed into messenger RNAs (mRNAs) in the nucleus (in eukaryotes), followed by mRNAs (if the gene is protein coding) getting translated into proteins in the cytoplasm. This is essentially a process of information transfer between information-carrying polymers; DNA, RNA and proteins, known as the “central dogma” of molecular biology (see Figure 1.2 for a summary). Proteins are essential elements for life. The growth and repair, functioning and structure of all living cells depend on them. This is why the gene is a central concept in genome biology, because a gene can encode information for proteins and other functional molecules. How genes are controlled and activated dictates everything about an organism. From the identity of a cell to response to an infection, how cells develop and behave against certain stimuli is governed by the activity of the genes and the functional molecules they encode. The liver cell becomes a liver cell because certain genes are activated and their functional products are produced to help the liver cell achieve its tasks.
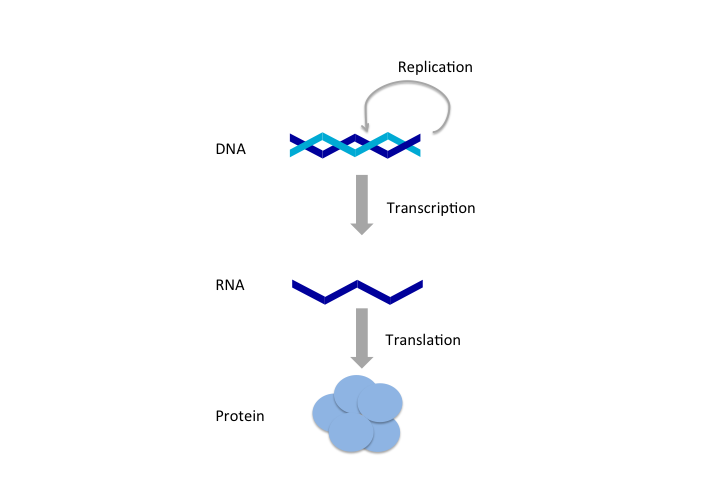
FIGURE 1.2: Central Dogma: replication, transcription, translation
1.1.3 How are genes controlled? Transcriptional and post-transcriptional regulation
In order to answer this question, we have to dig a little deeper into the transcription concept we introduced via the central dogma. The first step in a process of information transfer - the production of an RNA copy of a part of the DNA sequence - is called transcription. This task is carried out by the RNA polymerase enzyme. RNA polymerase-dependent initiation of transcription is enabled by the existence of a specific region in the sequence of DNA - a core promoter. Core promoters are regions of DNA that promote transcription and are found upstream from the start site of transcription. In eukaryotes, several proteins, called general transcription factors, recognize and bind to core promoters and form a pre-initiation complex. RNA polymerases recognize these complexes and initiate synthesis of RNAs, the polymerase travels along the template DNA and makes an RNA copy (Hager, McNally, and Misteli 2009). After mRNA is produced it is often spliced by spliceosome. The sections, called ‘introns’, are removed and sections called ‘exons’ left in. Then, the remaining mRNA is translated into proteins. Which exons will be part of the final mature transcript can also be regulated and creates diversity in protein structure and function (See Figure 1.3).
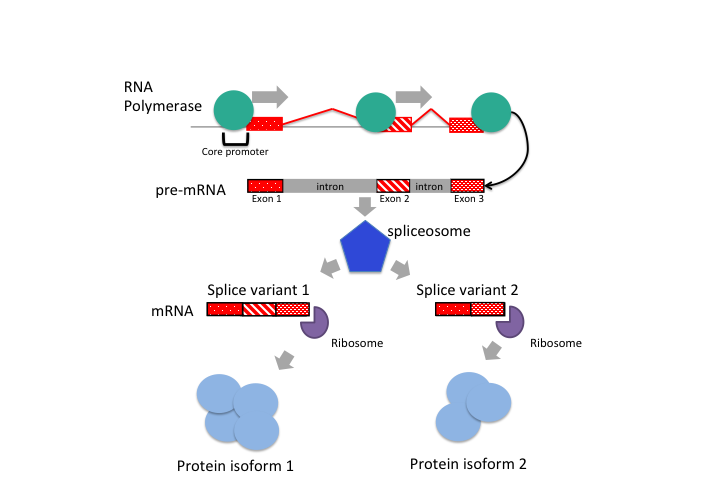
FIGURE 1.3: Transcription can be followed by splicing, which creates different transcript isoforms. This will in return create different protein isoforms since the information required to produce the protein is encoded in the transcripts. Differences in transcripts of the same gene can give rise to different protein isoforms.
Contrary to protein coding genes, non-coding RNA (ncRNAs) genes are processed and assume their functional structures after transcription and without going into translation, hence the name: non-coding RNAs. Certain ncRNAs can also be spliced but still not translated. ncRNAs and other RNAs in general can form complementary base-pairs within the RNA molecule which gives them additional complexity. This self-complementarity-based structure, termed the RNA secondary structure, is often necessary for functions of many ncRNA species.
In summary, the set of processes, from transcription initiation to production of the functional product, is referred to as gene expression. Gene expression quantification and regulation is a fundamental topic in genome biology.
1.1.4 What does a gene look like?
Before we move forward, it will be good to discuss how we can visualize genes. As someone interested in computational genomics, you will frequently encounter a gene on a computer screen, and how it is represented on the computer will be equivalent to what you imagine when you hear the word “gene”. In the online databases, the genes will appear as a sequence of letters or as a series of connected boxes showing exon-intron structure, which may include the direction of transcription as well (see Figure 1.4). You will encounter more with the latter, so this is likely what will pop into your mind when you think of genes.
As we have mentioned, DNA has two strands. A gene can be located on either of them, and the direction of transcription will depend on that. In the Figure 1.4, you can see arrows on introns (lines connecting boxes) indicating the direction of the gene.
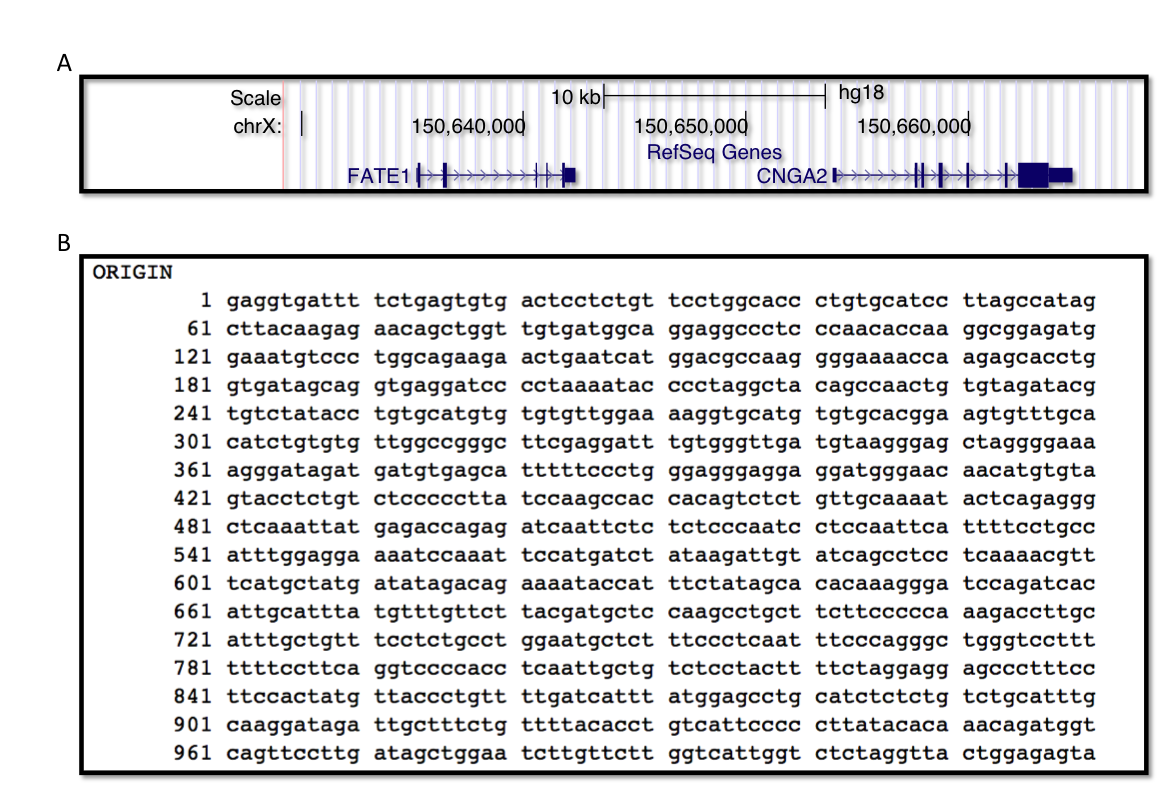
FIGURE 1.4: A) Representation of a gene in the UCSC browser. Boxes indicate exons, and lines indicate introns. B) Partial sequence of FATE1 gene as shown in the NCBI GenBank database.
References
Alberts, Bray, Lewis, Raff, Roberts, and Watson. 2002. Molecular Biology of the Cell. 4th ed. Garland.
Eilbeck, Lewis, Mungall, Yandell, Stein, Durbin, and Ashburner. 2005. “The Sequence Ontology: A Tool for the Unification of Genome Annotations.” Genome Biology 6 (5): R44.
Hager, McNally, and Misteli. 2009. “Transcription Dynamics.” Molecular Cell 35 (6): 741–53.